



AI and the Problem of Knowledge Collapse
Not just true or false, but the diversity of LLM outputs is important

The rapid proliferation of artificial intelligence is reshaping the way we think about knowledge, learning, and even culture. In AI and the Problem of Knowledge Collapse, just published at AI & Society, I consider what happens when the information we rely on is increasingly mediated by AI systems.
The Core Issue
Most people's concern about AI is how it will affect society - what happens when we use large-language models (LLMs) like ChatGPT in everything from emails to scientific research to therapy and medicine? Already the internet and social media is being filled up with texts that are AI-generated or by humans interacting with AI, and of course there is almost no transparency in labeling to know when this is the case. So looking into the future where this will presumably become more pervasive, will the use of AI in generating and curating content ultimately harm human knowledge itself?
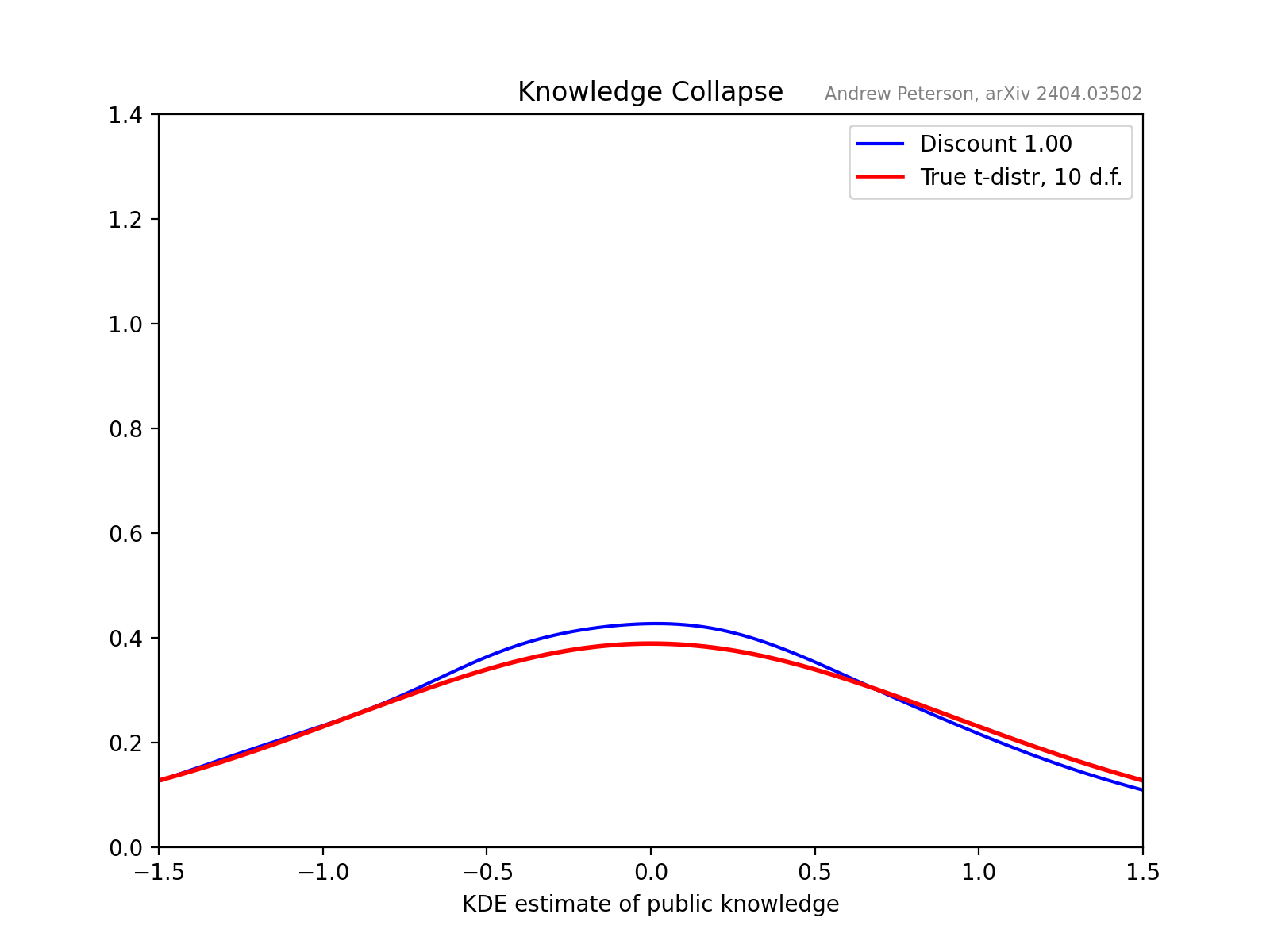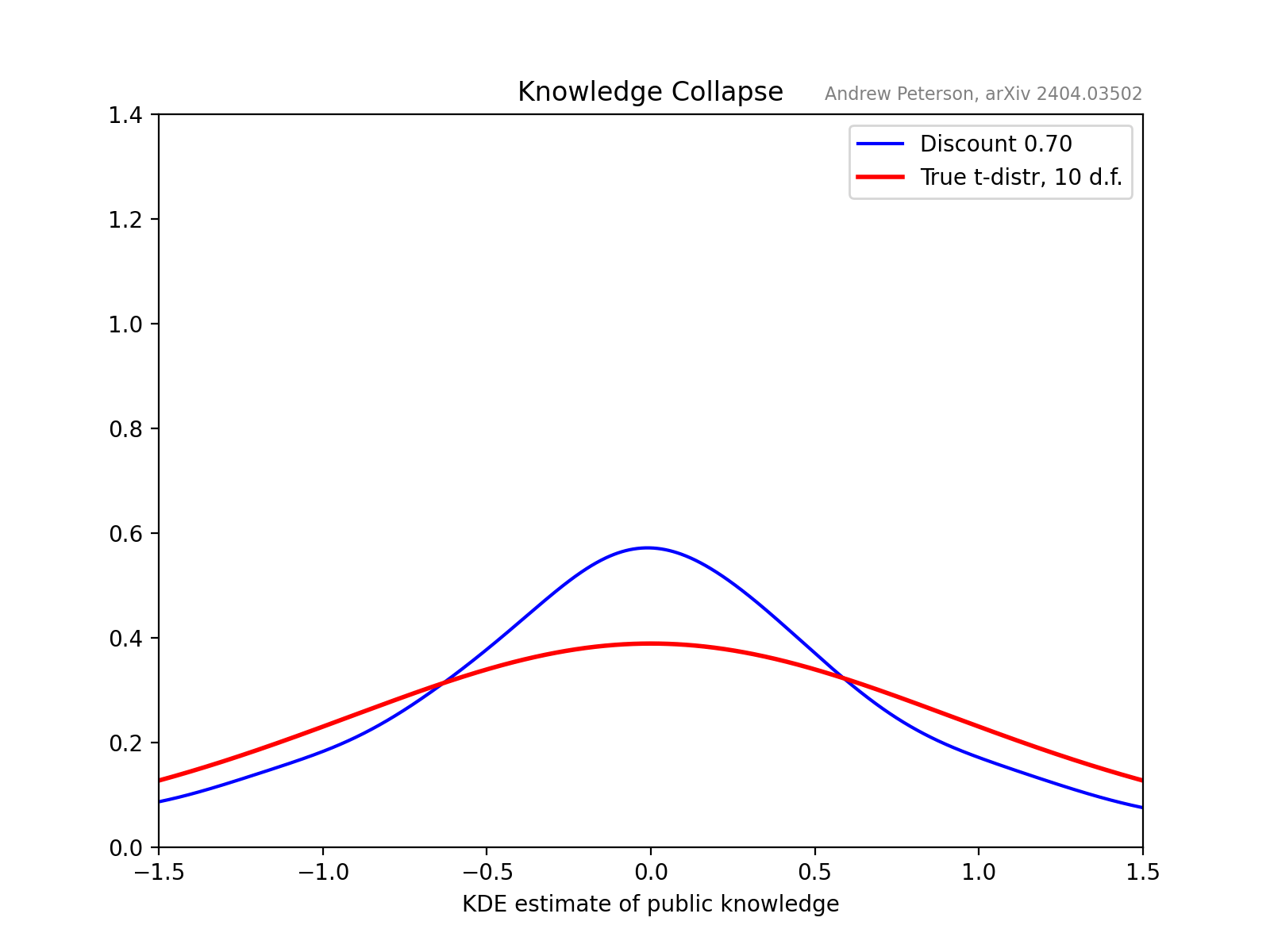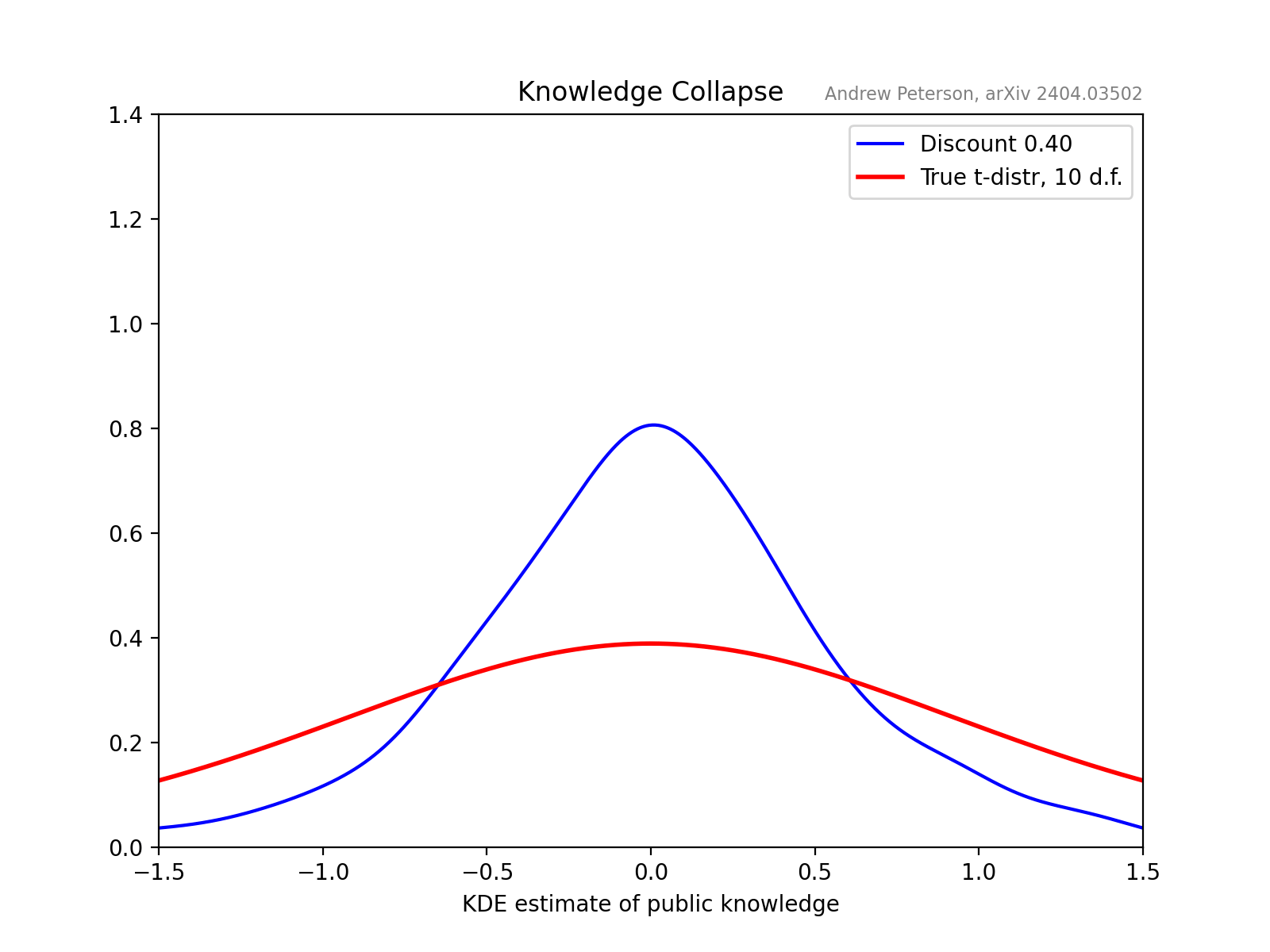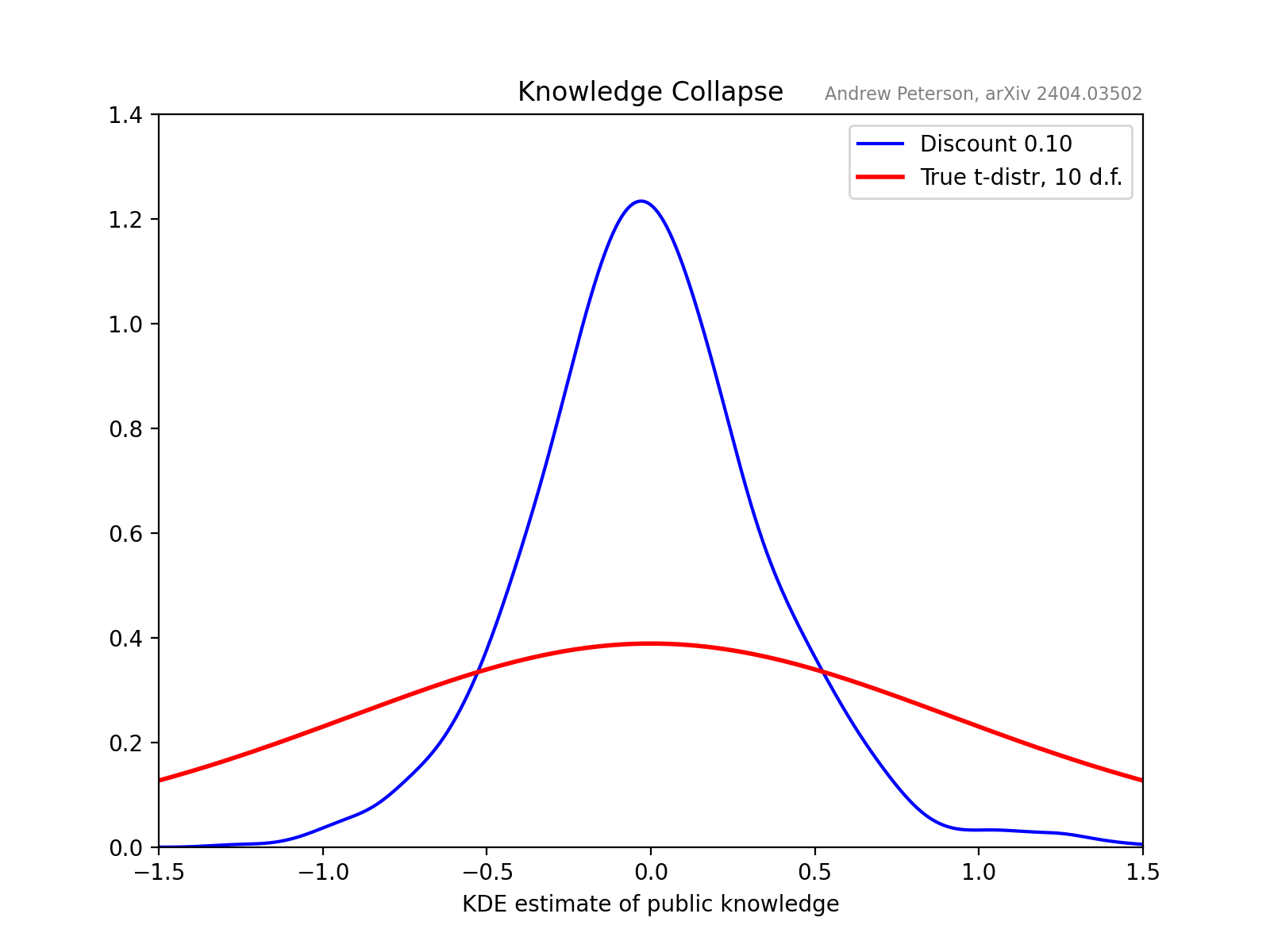
A key observation is that future knowledge-systems will be built on recursive AI input. Its not just that we might read a ChatGPT-generated summary of a book, but we will be, for example, tutored by an AI that includes as input AI-generated books and internet texts, written by humans who read Wikipedia edited by AI-bots, etc.
The concept of “knowledge collapse,” is a societal analogue to the well-documented phenomenon of “model collapse” in AI systems. When language models are trained on outputs from earlier models, their understanding degrades over generations. The tails of the knowledge distribution—eccentric, rare, and potentially transformative perspectives—are progressively truncated. Inversely, if we, as humans, increasingly ‘trained’ (educated by, informed by) AI-generated content, could our collective understanding suffer a similar fate?

Strategic Choices and the Torch-bearers of Knowledge
An objection, however, is that unlike AI models, humans can make conscious decisions about their sources of knowledge. People who use LLMs don’t always love the output, sometimes they think “this is a poor summary” and go read the original, while other humans refuse to use AI at all. That helps, because if there are enough of these “eccentric” humans who create a public good by preserving the “long-tail” knowledge that AI summaries ignore, they can keep alive the diversity of human thought.
To investigate this, the paper develops a model of a learning community where individuals choose between cheap AI information (from a truncated distribution) and more costly, more comprehensive sources of information.
Empirical Measure of Diversity of AI Outputs
The article also considers a new kind of problem with AI-generated outputs. While its well-known that LLMs can hallucinate or exhibit biases, I show how their outputs can be distributionally flawed, biased towards the center and lacking in diversity. As seen in the response to the paper on Reddit and HackerNews, many people who have used LLMs have had this experience. But for some uses, getting the bland, middle-of-the-road answer is exactly what you want. Its great when you want to know what the conventional view is on some topic (to learn the basics, or in order to see if your own hypothesis is different). But it can be frustrating when you feel like you're missing out on the diversity of eccentric perspectives that give the long-history of human thought its richness.
In the paper I consider the example of asking “What does the well-being of a human depend on according to philosophers?” The answers the LLMs give are not so much wrong - they generally mention Plato, Aristotle, and so on as you’d expect. But if you repeat that question over and over again, they just keep giving you the obvious examples, so that if you didn’t know any better you would think all of philosophy and ethics consisted of Aristotle, utilitarianism, and Existentialism.
Those are fine answers of course, but the repetition of these also excludes other perspectives (in particular those presumably less-well represented in the corpus of internet texts the models are trained on). In a corpus of repeating this process many times, there are 392 mentions of “Martin Seligman”, an American psychologist who has written on happiness and well-being, while only 62 for Al-Ghazali, and 52 for Al-Farabi two of the most influential (Islamic) philosophers of all time.

Towards solutions: Encouraging diversity
I do explore to what extent different prompting can encourage greater diversity, with five different prompts. This helps, as shown in the plot above, but is also insufficient. To really make progress, the typical machine learning approach would be to define a benchmark and then let researchers throw different approaches to see what works best. That would be a good extension of this work, but one of the challenges of implementing the paper already is creating a setting in which LLM outputs can vary (e.g. across a distribution) but then can still be coded in a programmatic way.1
Perhaps more useful for most people is to reflect on how we use AI in our everyday lives. The article suggests we actively think about what is missing in AI summaries, that we sometimes spend the extra effort to dig deep into topics and find perspectives that go against the grain. And beyond individual efforts, we of course need to do more to support real journalists and scientists who provide the insights that are then parroted by AI. The model also suggests the need to provide public funding for the preservation of arcane parts of knowledge that might otherwise be neglected in a purely profit-driven, race-to-the-cheapest information ecosystem. (I know, as an academic you expected me to oppose such an idea…but it is a community that includes figures such as Adam Smith.)
For more
AI & Society full text (viewable but gated)
For irony, if you don’t want to read the paper, you can listen to this AI-generated audio summary by NotebookLM, which hallucinates at one point, but is impressive in a number of ways.
See also this HackerNoon writeup, and the arXiv AI video (though less fun than the above):